現今面對快速變化的世代,災難發生令人措手不及,例如疫情啦,洪水災難啦,甚至是營運系統故障,很多時候我們需要預先做判斷,預先做出正確的決定,超前部署才能將傷害降到最低。而這些判斷的來源可能就是根據大量的數據,預先沙盤推演建立可能的模型,然後事先做好相應的對策。所以資料扮演非常關鍵的角色,能夠對資料做有效的統整及分析就是資料科學的領域。
要活用資料並洞悉資料的含義,你必須學習資料科學及機器學習及深度學習等領域。現今可運行資料科學的環境非 Linux 莫屬。Mac 電腦並沒有 Nvidia GPU 可選。Windows 電腦也不具備資料科學整合的應用環境,即便在Windows使用 WSL 運行 Ubuntu ,那用在機器學習的領域也是非常有限。你其實需要的是ㄧ台 Ubuntu 工作站或伺服器搭配 Nvidia GPU 來做模型訓練的工作。關於機器學習的套件有非常多,但是有完整整合及測試的就推 Nvidia RAPIDS。
要運行 Nvidia RAPIDS 需要的硬體設備需求如下
- i7/i9 Intel CPU or Ryzen 7/9 from AMD
- At least 16GB of RAM, preferred 32GB or more
- NVIDIA GPU – there are RTX or Quadro devices for professional workstations but a gaming GPU from 20XX or 30XX series would be good as well
環境部署:
作業系統安裝: 首先安裝好 Ubuntu Desktop (工作站) 或是 Ubuntu Server (帶有GPU 的伺服器)。建議使用 20.04 LTS 版本,享有較長時間的穩定更新及技術支援。
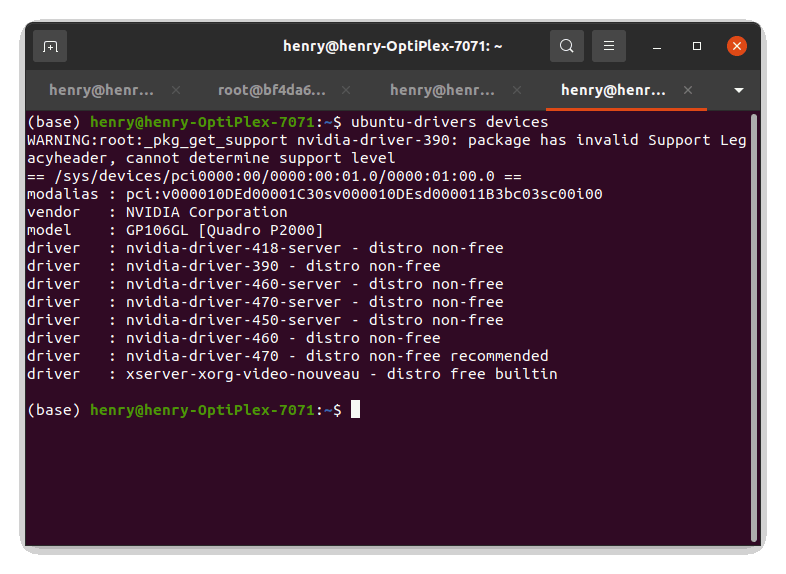
Nvidia 驅動程式:這部份在 Ubuntu 20.04 安裝時已整合Nvidia 專屬驅動程式了。例如下面指令查到系統的顯卡是 Quadro P2000及driver 版本。
Docker 安裝: 部署資料科學工作站使用容器是最方便的方式,因爲軟體有太多相依性,整個打包在容器內會是比較理想的方式。而且容器可以在本地端或是雲端等自由遷移。唯一的缺點是你必須熟悉 docker 的指令操作。
sudo apt update sudo apt upgrade sudo apt install docker.io
設定開機後自動啟動docker
sudo systemctl enable --now docker
Nvidia toolkit 安裝: 要讓docker 容器可以運用 GPU 來執行資料科學運算,必須執行 Nvidia toolkit 安裝。首先用文字編輯器產生一檔案 nvidia-container-runtime-script.sh,內容如下。然後執行此程式,並重啟docker。
curl -s -L https://nvidia.github.io/nvidia-container-runtime/gpgkey | \ sudo apt-key add - distribution=$(. /etc/os-release;echo $ID$VERSION_ID) curl -s -L https://nvidia.github.io/nvidia-container-runtime/$distribution/nvidia-container-runtime.list | \ sudo tee /etc/apt/sources.list.d/nvidia-container-runtime.list sudo apt-get update
sudo ./nvidia-container-runtime-script.sh sudo systemctl restart docker
Nvidia RAPIDS data science stack :機器學習的軟體套件很多,使用 RAPIDS 可以快速建立起測試及開發的環境。

RAPIDS 包含:
cuDF – 這是一個基於 Apache Arrow 的數據幀操作庫,可加速數據的加載、過濾和操作,用於模型訓練數據準備。核心加速的 CUDA DataFrame 操作原語的 Python 綁定反映了 Pandas 界面,用於 Pandas 用戶的無縫入門。

RAPIDS 包含:
cuDF – 這是一個基於 Apache Arrow 的數據幀操作庫,可加速數據的加載、過濾和操作,用於模型訓練數據準備。核心加速的 CUDA DataFrame 操作原語的 Python 綁定反映了 Pandas 界面,用於 Pandas 用戶的無縫入門。
cuML – 此 GPU 加速機器學習庫集合最終將提供 Scikit-Learn 中可用的所有機器學習算法的 GPU 版本。
cuGRAPH – 這是一個框架和圖形分析庫的集合
Nvidia data science stack 安裝步驟:
開始建立data science stack 容器
Nvidia data science stack 安裝步驟:
sudo git clone https://github.com/NVIDIA/data-science-stack cd data-science-stack ./data-science-stack setup-system你可以使用下面指令查一下driver 是否安裝正確
開始建立data science stack 容器
sudo ./data-science-stack build-container執行data science stack容器
sudo ./data-science-stack run-container當容器執行後,輸入網址 http://localhost:8888 即可以進入jupyter notebook管理畫面
Tensorflow 容器建立: Tensorflow 是機器學習最常用到的開源套件。
docker pull nvcr.io/nvidia/tensorflow:20.12-tf2-py3 sudo mkdir ~/shared_dir建立tensorflow 容器
sudo docker run --rm --gpus all -it --shm-size=1g --ulimit memlock=-1 --ul imit stack=67108864 -v ~/shared_dir:/shared nvcr.io/nvidia/tensorflow:20.12-tf2 -py3
下面這樣就是進入tensorflow 容器了,更多的容器類型請參考 Nvidia NGC

以上就是簡單配置資料科學運算環境的說明。如果你對 docker 容器的運作方式不太了解,最好事先上網查一下docker 操作方式。因爲很多大型的機器學習是用K8S 叢集在跑,這些都是使用 docker 容器做跨機器的運算及資源調度。至於要在本地端或是雲端做資料運算,我建議開發及測試一定要在本地端,等確認要進行生產環境的部署就可以考慮使用邊緣運算或是上雲,畢竟資料還是有隱密性,全部資料上雲也是需要儲存空間及時間。而邊緣運算則會有較低的延遲性,就看應用的方式來選擇最佳的生產環境了。